How NYPL Labs Turns Physical Data Into Digital Knowledge, a Hacks/Hackers NYC guest post
Suggest edits
[Guest post by Dave Riordan, Product Manager, NYPL Labs]
Last week, we had the pleasure of hosting and speaking at the incredible Hacks/Hackers NYC meetup, a collective of some of the most talented and interesting folks in New York with a bent toward building a better-informed citizenry through journalism, technology and design. They welcomed us and we fit right in.
Rather than have myself and Ben Vershbow do our traditional dog-and-pony show (that poor, poor pony), the entire Labs team got up on stage to share some of our most interesting projects and technical investigations, several of which were shown for the first time.
Here’s a quick rundown of what we covered:
pssst – if you want to follow along, we’ve posted our slides from the evening. (PDF | Scribd)
Ben Vershbow, Labs’ founder and manager covered the philosophy and history of Labs, along with 4 of our projects:

Hacks/Hackers needed 3D glasses to get the full Stereogranimator effect.
- NYPL Historical Geospatial Program, including the Map Warper, which transforms pictures of old maps into actionable geospatial data, the NYC Chronology of Place, our historical gazetteer for New York, and our Ghost Map prototype, which unifies historical city directories with historical maps.
- The Stereogranimator, which transforms vintage 3D photographs called stereographs into pseudo-3D wiggle-GIFs — mashing up vintage photography with vintage web – and real 3D anaglyphs.
- What’s on The Menu, where we put our historical restaurant and banquet menu collection online and ask volunteers to help turn them into a structured dataset of culinary and economic history (and the first official API from NYPL).
- DirectMe NYC: 1940, a rapid-response tool infused with the knowledge of our Milstein Division librarians we built to make the 1940 US Federal Census immediately usable by fusing old phonebooks with geneological tools, old maps, and NY Times headlines. In a fortuitous coincidence Zeehsan Lakhani, our developer emeritus behind the project, happened to be in the audience. And look: we found J.D. Salinger!
In addition, Ben plugged NYPL’s Digital Collections API, NYPL’s open API that powers our new Digital Collections site.
Paul Beaudoin, data scientist/oil painter, shared our prototype of Ensemble, a crowd-powered data mining app designed to transform our theatre program collection from the New York Public Library for the Performing Arts into a dataset of historical performances and performers. He took us on a tour of parallel efforts in academia, newsrooms and citizen science, and discussed some of the challenges of figuring out how to extract information with a highly complex data model from documents with widely divergent layouts and templates. We also got to see a custom visualization of how many users come together on Ensemble to generate a consensus of what the materials accurately represent. Also see these two related citizen science projects from Zooniverse — with whom NYPL Labs is partnering, thanks to the NEH — to build an open source transcription engine that can make projects like oldweather.org and notesfromnature.org easier to set up.
Trevor Thornton and Matt Miller, the only members of Labs with actual Library degrees (they make the rest of us slackers look good), shared the approach they’re taking to designing NYPL’s brand spanking new Archives portal, where researchers can go to work with NYPL’s over 8,000 archival collections (unique, unpublished materials — ‘the papers of ’, ‘the records ’. First, Trevor Thornton gave a hilarious “everything you wanted to know about archives but didn’t know to ask” overview, then took us through a tour of the underlying systems that power the archives portal, much of which was designed to treat archival finding aids as data rather than simply as documents. Then he turned things over to Matt Miller to show off some of the cool new interfaces this approach makes possible. They queued up the Jack Kerouac collection, and showed off two hidden features, triggered via an ode to the console cheat codes of the ’80s:
- By typing “minime” on the Detailed Description, it brings up The Navigator, a Sublime Text-inspired pane that lets you navigate a finding aid based on the structure of the text.
- By typing “networksarecool” on the Detailed Description, it brings up a network analysis of the archival collection, creating a subject-driven network graph created by the archival arrangement.
Additionally, Matt showed off a new visualization of the entire NYPL Catalog based on Subject Headings, designed to allow spatial exploration of the library’s overall holdings; hopefully the first step toward creating new approaches that will make NYPL’s entire collections more approachable and navigable. As a bonus, check out another quick visualization Matt made (but didn’t have time to show): 1,001 full-text archival finding aids color-coded by average date of each collection’s components.
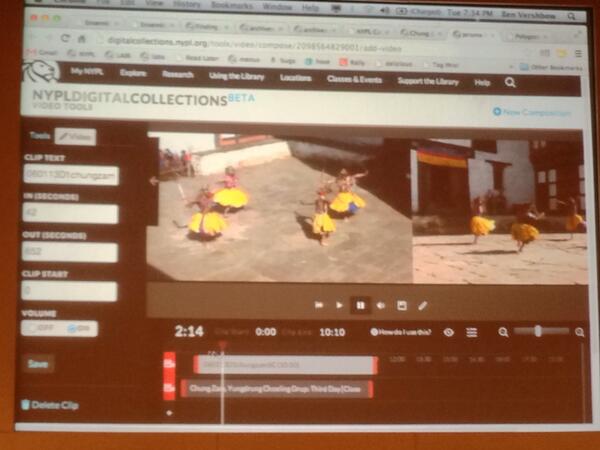
Brian Foo of NYPL Labs demonstrated his video mashup and annotation tool.
Brian Foo, our resident breakdancer/fine artist/Kickstarter-er extraordinaire, demoed the video juxtaposition / mashup tool he built for the Jerome Robbins Dance Division at the Library for the Performing Arts, which is basically a browser-based video editor powered by Mozilla’s Popcorn.js.
Due to rights restrictions, most of the collection can only be viewed while onsite at the Library for the Performing Arts. But we were able to juxtapose several multi-camera shots of ritual dance from Bhutan, then mashed it up with some fly moves and beats from The Jabbawockeez. And there wasn’t time to show it off onstage, much of the inspiration for the juxtaposition tool came from one of Brian’s own art works, Joyblaster, a series of video pieces where people’s personal stories are reconstructed from multi-frame YouTube videos. You can grab some of the code used to power the juxtaposition tool, namely the Brightcove player for Popcorn.js and several plugins for Video.js.

Teh Vectorizer by NYPL Labs is like OCR for maps. And it can detect additional features on its test set of hand-drawn maps.
Mauricio Giraldo, our mad scientist interaction designer, took us on a tour through the insides of Teh Vectorizor, his groundbreaking tool that crunches our huge backlog of insanely detailed historical insurance maps — formerly turned into data via hand-crafted artisanal processes (which took 3 years to get through 3 boroughs) — into largely automagically generated data through a frankenscript of open source tools. But because it’s not perfect yet, he also showed off an early version of our map data improvement game, which we’re tentatively calling Polygonzo, a mobile game that lets people check the Vectorizer’s accuracy. Ultimately, we’d like to make this a mobile app that subway-dwelling New Yorkers can play offline, maybe give Angry Birds a run for their money. Keep an eye out in the coming weeks for a first release…
Finally, we had Dan Vanderkam. Dan’s a friend of Labs and the creator of Old SF, a site that lets you navigate the historical street photographs of San Fransisco from the SF Public Library. Dan demoed the upcoming Old New York project he’s been working on with 40,000+ street photographs from the Library’s Milstein Division of Local/U.S. History & Genealogy. He also covered his process for finding and liberating pictures from inside other pictures as many of the Milstein images are actually 2-3 pictures per image, making them normally too small to see in fine detail. Dan figured out a way to extract the pictures within pictures, and he helped us generate larger versions that we’ll hopefully be incorporating and will be available when Old New York launches later this year.
At the end, I put out a final call for everyone present to seek us out, share their ideas, their possible collaborations, their research questions. The mission of Labs and The Library is far too big for us to accomplish on our own and the hacker/researchers of today are going to be blazing the path for all of our users in the near future. It’s gonna be awesome.
Even if you weren’t able to make it, that applies to you too. Drop us a line. We’re labs@nypl.org and @nypl_labs. Let’s build the public library of data together.